
The Four Pillars of Industrial Reliability: How Asset, Plant, Production, and Digital Reliability Drive Uptime, Energy Efficiency, and Throughput
Read Time: 5–6 minutes | Author – Kalyan Meduri

Plants that invest only in predictive maintenance on a few critical machines often still firefight—process bottlenecks, unreliable utilities, or untrusted analytics keep pulling them back into unplanned stops, unstable energy performance, and missed throughput targets. Even advanced predictive tools fall short without prescriptive actions that address root causes, coordinate across teams, and optimize energy alongside uptime.
Asset Reliability: Keeping Critical Machines Out of Trouble
Asset reliability is the ability of individual equipment—motors, pumps, gearboxes, fans, kilns, compressors, conveyors—to perform their intended function without failure under defined operating conditions.
In practice, it answers one question:
“Will this asset fail, and what can we do right now to prevent it? ”
When asset reliability is high, plants see:
- Reduced unplanned downtime : Early detection of degradation prevents sudden failures that disrupt production schedules and cause cascading operational losses.
- Lower maintenance cost per unit : Planned, condition-based interventions replace emergency repairs, reducing overtime, spare part wastage, and secondary damage.
- Improved workplace safety : Equipment failures often create hazardous situations; reliable assets reduce the risk of sudden mechanical or electrical incidents that endanger personnel.
- Extended equipment life : Operating assets within healthy limits minimizes excessive wear, preserving asset integrity and delaying capital replacement
How Asset Reliability Is Built
Modern reliability teams move beyond calendar-based PMs to continuous, sensor-driven visibility:
- Continuous condition monitoring using vibration, temperature, current, pressure, and process data to reveal misalignment, imbalance, looseness, lubrication issues, and bearing defects early.
- Clear understanding of dominant failure modes and degradation patterns per asset class (e.g., conveyor gearboxes vs. kiln drives vs. ID fans), so interventions are precise, not generic.
- Use of metrics like MTBF and Remaining Useful Life (RUL) to prioritize work, schedule stoppage, and quantify risk if an asset is run to the next window.
- Predictive and prescriptive maintenance that not only detects anomalies but prescribes specific actions—such as “realign motor–gearbox” or “inspect 4th-stage gear during next planned stop.”
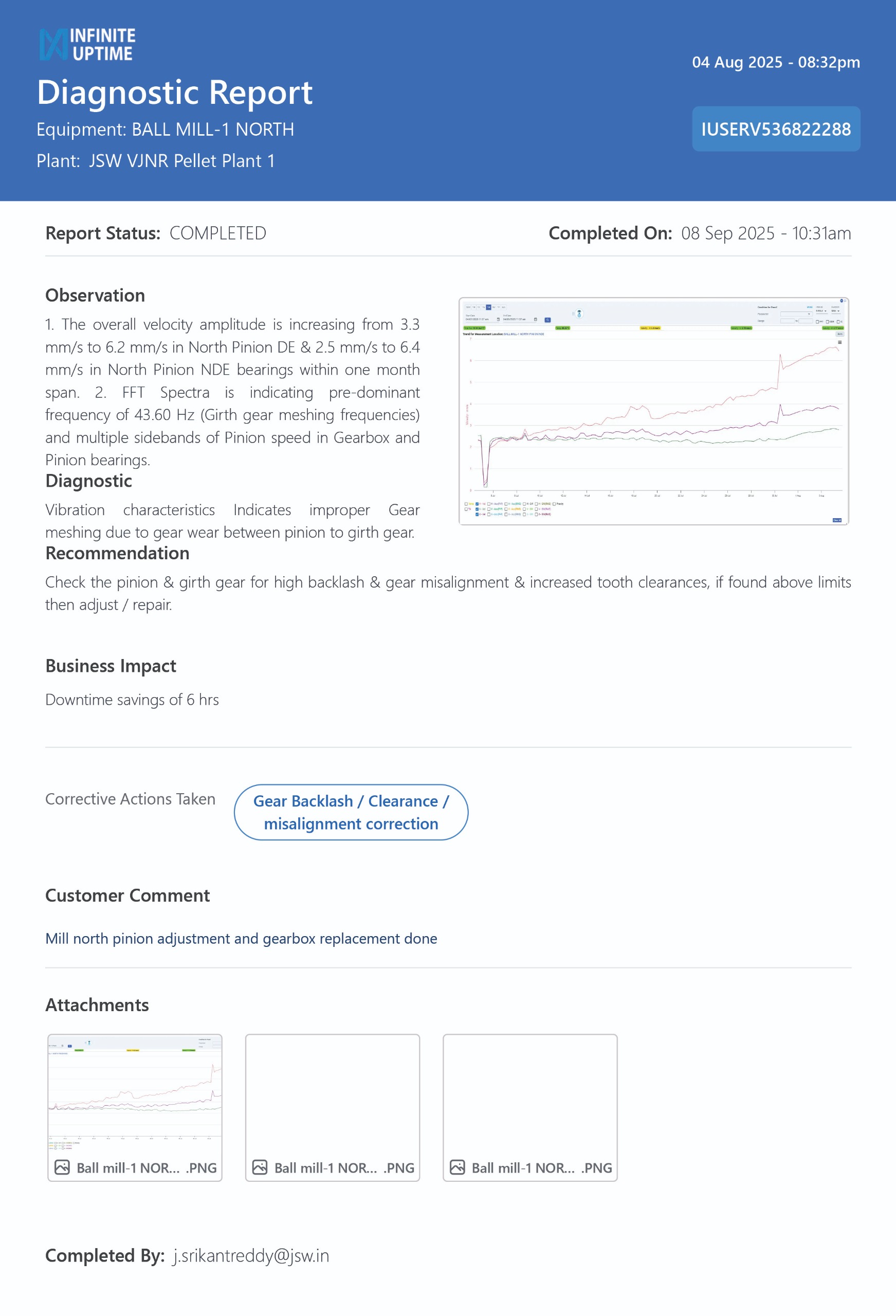
Steel example – Prescriptive ODR on ball mill
In a pellet plant ball mill, rising pinion-bearing vibration at the girth-gear meshing frequency triggered a diagnostic report that pinpointed improper gear meshing from wear and misalignment.
Prescriptive diagnostics guided the team to inspect pinion–girth gear backlash, tooth clearances, and alignment, then correct backlash, clearance, and misalignment within recommended limits.
By executing these actions before the fault escalated, the plant avoided an estimated six hours of ball mill downtime while stabilizing vibration at the pinion bearings—protecting a critical grinding bottleneck, safeguarding gear and bearing life, and preserving pellet throughput without a forced shutdown.
Plant Reliability: Making the Whole System Run as One
Plant reliability is the ability of the entire production system—asset/equipment, process trains, utilities, and supporting infrastructure—to run as designed without cascading failures or chronic instability.
It answers a tougher question than “Is each asset healthy? ”—it asks, “Will the plant stay stable, shift after shift, when everything is coupled together? ”
Even when individual assets are healthy, plants suffer if:
- Utility systems (power, compressed air, water, fuel, cooling) are unstable.
- Interdependencies and bottlenecks are poorly understood.
- Maintenance and operations pull in opposite directions on scheduling and priorities.
High plant reliability shows up as:
- Stable production schedules with fewer full-plant or line-level trips.
- Less “domino effect” from a single failure propagating into upstream and downstream losses.
- More coordinated decision-making between operations, maintenance, and energy teams.
How Plant Reliability Is Built
Reliability leaders treat the plant as an integrated network, not a list of assets:
- Mapping critical process paths, constraints, and failure propagation—for example, how a single ID fan or EP fan can halt a kiln and downstream grinding.
- Elevating reliability of utilities and support equipment to the same criticality as primary production assets, because a single weak utility can repeatedly trip production.
- Aligning maintenance windows, changeovers, and cleaning with production plans, so interventions protect—not disrupt—throughput and energy performance.
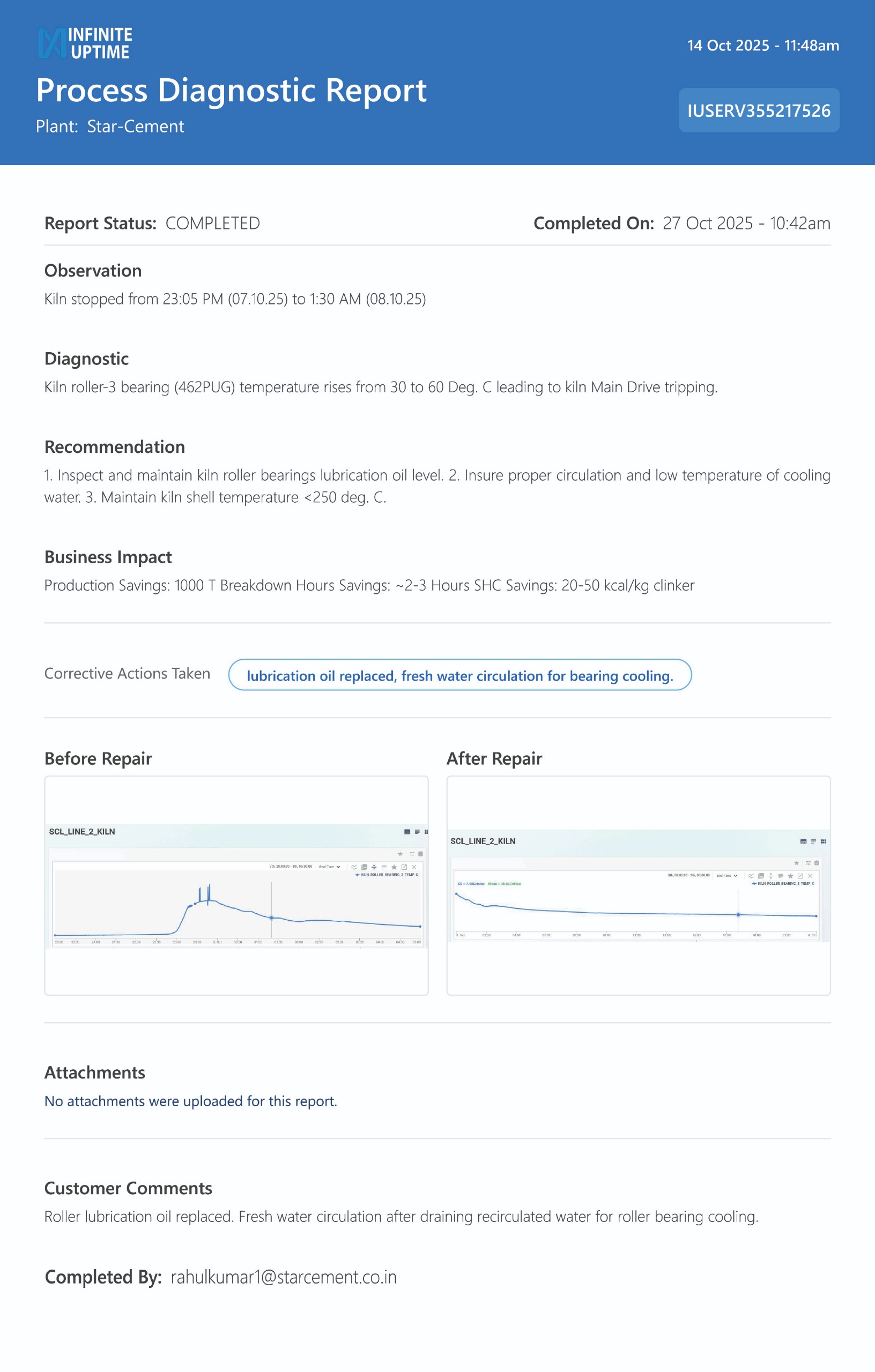
Cement example – kiln roller trip that destabilized the line
In a cement plant, the Line-2 kiln repeatedly stopped when Roller-3 bearing temperature spiked from about 30 to 60 °C, triggering main drive trips and halting the entire pyro line from 23:05 to 1:30 on a single night. A process diagnostic report traced the trips to inadequate roller-bearing lubrication and ineffective cooling water circulation, rather than a single mechanical defect.
The system prescribed plant-level actions—restore lubrication oil condition and level, improve cooling water circulation, and maintain kiln shell temperature below 250 °C—to stabilize the roller and protect the kiln drive. By closing these utility and process gaps, the plant avoided an estimated 2–3 hours of repeat breakdowns, safeguarded roughly 1,000 tons of clinker production, and cut specific heat consumption by 20–50 kcal/kg, transforming a recurring kiln-line vulnerability into a more reliable kiln system.
Production Reliability: Hitting Downtime, Throughput, and Energy & Process Efficiency Targets
Production reliability is about outcomes: delivering planned output at the required quality, cost, and energy intensity.
It answers: “Can we consistently meet what we promised—on unplanned downtime, energy & process efficiency, and throughput? ”
Key benefits of strong production reliability include:
- Meeting customer delivery commitments without expediting, last-minute overtime, or juggling orders.
- Stabilized energy consumption per ton, since stops, starts, and process swings are major drivers of energy waste in heavy industries.
- Lower scrap and rework because process conditions hold tighter around the target window.
How Production Reliability Is Built
Production reliability emerges when equipment, process control, and operational decisions are aligned:
- Throughput consistency: Minimizing micro-stoppages, speed losses, and chronic minor jams that rarely appear as “breakdowns” but erode output every shift.
- Quality stability: Tight control of process variables (e.g., kiln feed chemistry, paper moisture profile, rolling mill tension) to reduce off-spec batches and grade changes gone wrong.
- Smart response to unplanned downtime: Protecting bottlenecks, re-sequencing orders, and using prescriptive actions to minimize the production and energy impact of unavoidable stops.
- Maintenance aligned to production goals: Prioritizing interventions by their impact on throughput, energy per ton, and quality—not just asset condition scores.
Cement example – turning a complex plant into an outcome engine
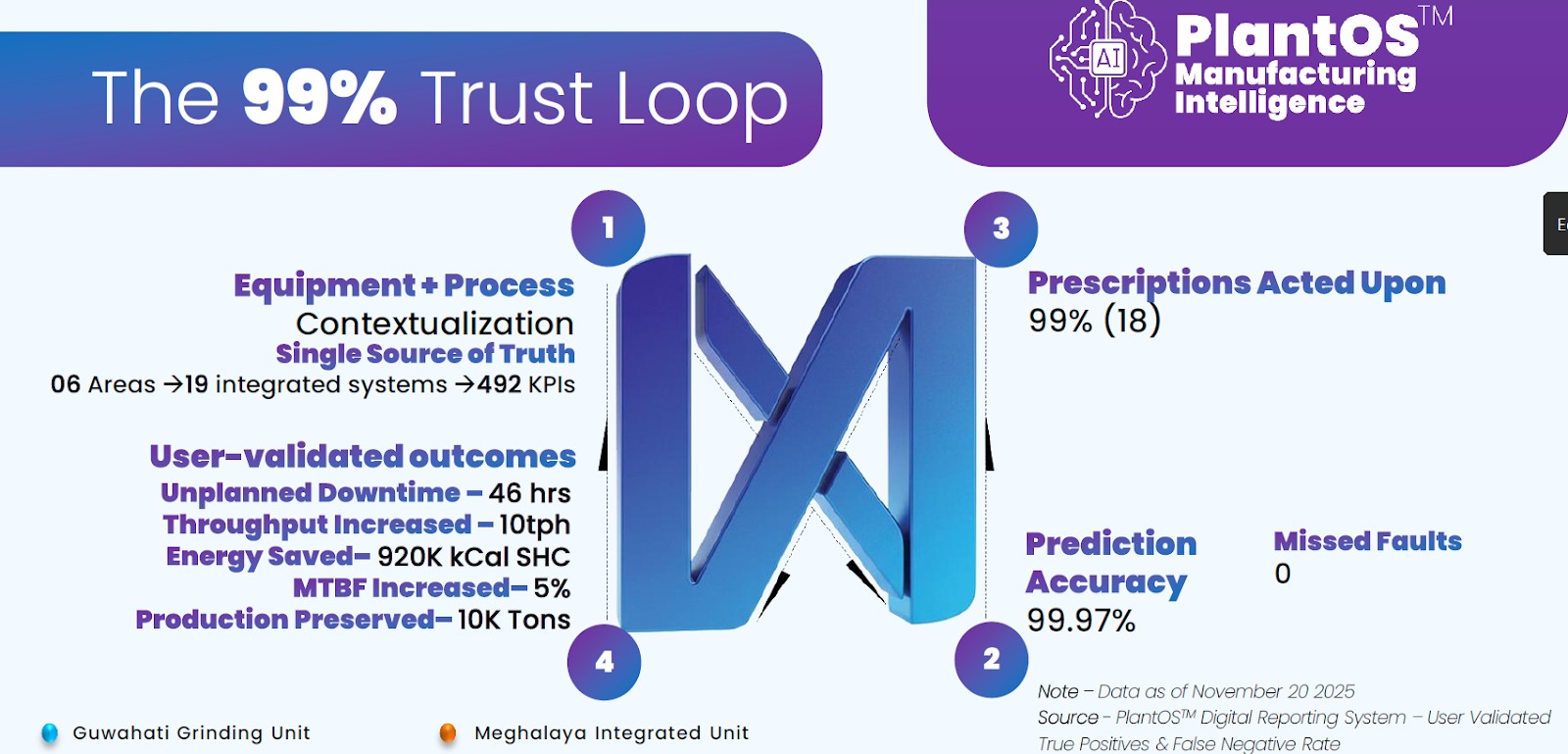
A leading cement producer in the Middle East used an AI‑driven plant platform to connect 6 functional areas, 19 systems, and 492 KPIs across mines, raw mills, kilns, WHRS, CPP, and grinding lines into a single, contextualized view of reliability and production. Within six months, prescriptive diagnostics and process recommendations eliminated 46 hours of unplanned downtime, lifted clinker line throughput by around 10 tph, and cut specific heat consumption by about 920,000 kcal—delivering a 10x ROI by simultaneously improving uptime, throughput, and energy efficiency rather than chasing isolated failures.
Digital Reliability: Trusting the Data Enough to Act
Digital reliability is the accuracy, consistency, and usability of digital systems that support operations—online condition monitoring, analytics platforms, AI models, dashboards, and alerts.
The core question is: “Can we trust these insights enough to take real action?”
Without digital reliability:
- Teams ignore alarms because of false positives and noisy data, leading to missed critical events.
- AI recommendations are viewed as “black box suggestions” and side-lined in favour of gut feel.
- Dashboards remain passive screens instead of embedded decision tools.
When digital reliability is high:
- Decisions become faster and more confident because signals are clean, models are validated, and recommendations are actionable.
- Alert fatigue drops as alerts are prioritized by risk, impact, and time-to-failure.
- Digital systems demonstrably improve uptime, energy & maintenance cost, and process efficiency.
How Digital Reliability Is Built
Reliability teams treat data and analytics with the same rigor as physical assets:
- Sensor and data quality management: Ensuring correct sensor placement, calibration, timestamping, and health checks to avoid “garbage in, garbage out.”
- Model explainability: Making sure users can see why an alert was raised (e.g., harmonics pattern, temperature trend vs. historical envelope) and what the likely failure mode is.
- Closed-loop validation: Comparing predicted failures and recommendations against actual outcomes, then retraining models and tuning thresholds for the plant’s specific equipment and duty cycles.
- Workflow integration: Delivering insights into existing maintenance, control room, and production workflows so they trigger work orders, reviews, or operating changes—not just graphs.
Digital reliability in modern plants is powered when your reliability platform can see everything, contextualize it fast, and be trusted almost every single time.
PlantOSTM does this by continuously ingesting both wired and wireless data streams—covering mechanical signatures (vibration, temperature), electrical behaviour (current, voltage, harmonics), and rich process context (flows, pressures, loads, recipes, setpoints)—into a single model of how the plant actually runs. Within weeks, this equipment and process data is contextualized across lines and systems, so the platform can distinguish whether an emerging issue is mechanical, electrical, or process-induced and prescribe the right action instead of just raising another generic alert.
Under the hood, PlantOSTM is an industry-trained, agentic industrial AI, trained on more than 85,000 equipment across 50+ asset types. This deep domain training allows it to recognize patterns specific to kilns, mills, fans, compressors, conveyors, and utilities, and to adapt its diagnostics and prescriptions to the way each asset operates in different process conditions.
On top of this unified data and domain layer, PlantOSTM achieves up to 99.97% prediction accuracy, meaning its anomaly and failure predictions align almost perfectly with real plant behaviour. Because these predictions are coupled with clear, targeted prescriptions—and those prescriptions consistently deliver value—plants see up to 99% prescription adoption rates on critical recommendations. This closes the 99% Trust Loop: high-fidelity predictions, high implementation of recommended actions, and continuous feedback from what actually happened in the field.
At scale, across 844 plants digitized globally, this trust loop is what turns digital reliability from theory into outcomes. Teams rely on the system to catch mechanical, electrical, and process-induced faults early; they act on the prescriptions because they’ve seen them work; and the platform proves its value in user-validated results—unplanned downtime avoided, throughput sustained or increased, and energy efficiency improved—rather than just in charts and dashboards.
How the Four Pillars Reinforce Each OtherThese pillars are deeply interconnected on the shop floor:
| Pillar | Primary focus | Core question answered |
|---|---|---|
| Asset reliability | Individual equipment | Will this asset fail, and when? |
| Plant reliability | System performance | Will the plant run smoothly end-to-end? |
| Production reliability | Outcomes | Can we reliably hit our plan on downtime, throughput, and energy per ton? |
| Digital reliability | Data & decisions | Can we trust the insights enough to act? |
A few common real-world patterns:
- A plant can have reliable assets but poor production reliability because bottlenecks, grade-change practices, or unstable utilities create chronic process disturbances.
- A plant may invest heavily in sensors and dashboards but still suffer low digital reliability; if alerts are noisy or non-actionable, the system will be bypassed, and value is lost.
- High digital reliability amplifies all other pillars—turning raw asset data into prescriptive actions that stabilize the plant and protect production commitments at lower cost.
For industrial leaders in sectors like steel, cement, mining, paper, chemicals, tires, and food, the path out of firefighting is to treat reliability as a four-pillar discipline: strengthen assets, stabilize the plant, lock in production outcomes, and build digital systems people actually trust and use.
Read More on Industrial Energy Efficiency

Prescriptive Maintenance + Energy Efficiency: A Practical Path to Stable Industrial Operations
In the United States, unplanned downtime costs manufacturers over $1...

Downtime Is Draining Your EBITDA: The Real Role of Industrial Energy Efficiency
Downtime rarely starts with a breakdown. It often begins quietly—through...

Why 95% of GenAI Projects Failed and How Prescriptive AI and the 99% Trust Loop Are Changing Manufacturing
In 2025, MIT reported that 95% of GenAI projects failed...